

<股市行情鑫东财配资>1分钟找出3000个交易因子?真相来了!手把手教你用Python实现
我用1分钟给股票找出了3000个交易因子,用过的人都发财了
炒股的人,做量化的人,甚至是不小心刷到财经视频的你……多多少少都听过“交易因子”这几个字。
听起来就很高级对吧?什么 动量因子
每次别人提起都眉飞色舞,好像掌握了什么财富密码,你问一句“啥是因子?” 他们:你不懂
他们:你不配
得了,我忍了好几年了。
今天,花姐我就带着键盘——不,带着良心,来给你 扒开交易因子的真面目 ,顺便还手把手教你:
怎么用 ,一分钟干出3000个因子,不是“瞎 #技术分享编的因子”,是真·能喂给模型、能配对策略、能拿去回测的那种!
要是你能跟着我整完,下次就轮到你对别人说:“这不是因子的问题,是你不会提。”
啥是交易因子? 简单点说,它就像股票市场里的“隐藏秘籍”。别人看 K 线、看均线、看 MACD,你看交易因子——直接抢跑三步。
那么问题来了:怎么才能快速、批量地生成交易因子?
我试过很多招,最后发现了一个宝藏库,堪称“因子工厂”,它的名字是—— 。
:一台会炼金的因子生成器
是一个专注于 时间序列特征提取 的 库,全称是 Time based on tests 。它的核心功能,就是从一段或多段时间序列中,自动提取出大量可用于机器学习建模的统计特征 。
这些特征,也就是我们常说的 因子 (在金融量化语境下)。
更具体一点, 内置了上百种特征计算方法,涵盖常见的统计量(如最大值、最小值、平均值、方差、偏度、峰度)、频域特征、小波变换、傅里叶变换、复杂度指标、变化率指标等,甚至还有一些你连听都没听过的“奇葩特征”——什么 、 、e ,只要能用数学刻画时序,它都能榨出来。
你甚至都不用自己去定义特征函数,它会把能提的都给你提一遍,一口气喂你几千个。
它的设计初衷其实是面向工业 IoT 领域多因子量化选股策略,比如设备预测维护之类的1分钟找出3000个交易因子?真相来了!手把手教你用Python实现,但它天生适合金融时间序列。尤其是我们搞量化、做选股、因子挖掘这类场景,数据形态几乎一模一样。
说白了, 就是把“写因子”这件原本需要金融知识、经验积累、血泪教训的事,变成了“数据一扔,特征全来”的自动化流程。
当然,它的输出并不是终点,你还需要后续做筛选、降维、建模、回测。但就“因子发掘”这个环节而言,它极大地降低了门槛,是初学者和实验驱动型开发者的一大利器 。
不过话说回来, 也不是没有毛病—— 它有时候提的因子 重复性强、冗余度高
所以用得好是一把宝剑,用不好就是因子垃圾场。怎么用,咱一会儿慢慢讲。
思路全景
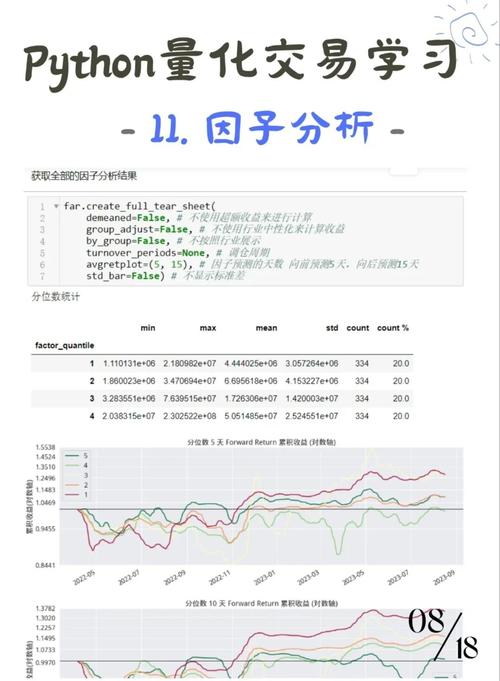
今天我们以 为例,教大家如何从头开始提取交易因子。
我们要干的事可以分 3 步走:
获取 历史行情 + 衍生技术指标用 从行情+指标中自动提取“时序特征因子”筛选出有用的因子Step 1:获取 数据 + 计算技术指标
我们选用 沪深(.SH) ,通过 获取过去两年的日线数据,并计算常见的技术指标(MACD、RSI、KDJ)。
import akshare as ak
import pandas as pd
import talib
from datetime import datetime, timedelta
symbol = "510300" start_date = (datetime.today() -
df = ak.fund_etf_hist_em(symbol=symbol, period="daily", start_date=start_date, end_date='20250520')
df = df.rename(columns={ "日期": "date", "开盘": "open", "收盘": "close", "最高": "high", "最低": "low", "成交量": "volume", }) df['date'] = pd.to_datetime(df['date']) df = df.sort_values('date').reset_index(drop=True)
df['rsi'] = talib.RSI(df['close'], timeperiod=14)
macd, macdsignal, macdhist = talib.MACD(df['close'], fastperiod=12, slowperiod=26, signalperiod=9) df['macd'] = macd df['macds'] = macdsignal df['macdh'] = macdhist
slowk, slowd = talib.STOCH( df['high'], df['low'], df['close'], fastk_period=9, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0 ) df['kdjk'] = slowk df['kdjd'] = slowd df['kdjj'] = 3 * slowk - 2 * slowd
df = df.dropna().reset_index(drop=True)
df.to_csv("01data.csv",index=False)
Step 2:用 自动提取因子特征
接下来,我们将数据转换为 需要的格式,并从中提取“时间窗口内的统计特征”。
库安装命令
pip install tsfresh
from tsfresh import extract_features
from tsfresh.utilities.dataframe_functions import impute
from tsfresh.feature_extraction import EfficientFCParameters
from tqdm import tqdm
import warnings
import pandas as pd
df = pd.read_csv("01data.csv") df['date'] = pd.to_datetime(df['date'])
warnings.filterwarnings("ignore", category=RuntimeWarning, module="tsfresh.utilities.dataframe_functions")
WINDOW_SIZE = 20 features_list = []
print(f"开始提取滑动窗口特征,每个窗口长度为 {WINDOW_SIZE}...")
for i in tqdm(range(WINDOW_SIZE, len(df))): df_window = df.iloc[i - WINDOW_SIZE:i].copy() tsfresh_df = df_window[['date', 'close', 'volume', 'rsi', 'macd']].copy() tsfresh_df['id'] = 0
df_long = tsfresh_df.melt(id_vars=["date", "id"], var_name="kind", value_name="value") df_long.rename(columns={"date": "time"}, inplace=True)
features = extract_features( df_long, column_id="id", column_sort="time", column_kind="kind", column_value="value", default_fc_parameters=EfficientFCParameters(), n_jobs=0, disable_progressbar=True ) impute(features)
features.columns = [f'feature_{col}' for col in range(features.shape[1])] features['date'] = df.iloc[i]['date'] features_list.append(features)
df_all_features = pd.concat(features_list, axis=0).reset_index(drop=True) df_all_features.to_csv("02data.csv", index=False)
print(df_all_features.head())
print("******************特征提取完毕**********************")
运行完以后我们就得到了 ... date 总计3107个因子了
Step 3:因子这么多,我该用哪几个?
因子提出来了,下一步当然就是—— 挑出“有用的因子” ,也就是 特征选择( ) 这一步。咱不能全都上,不然模型就容易陷入高维灾难、过拟合,甚至运行慢还没提升效果。
常见的因子筛选方法主要有以下几种:1. 过滤法( ) —— 快速初筛 典型方法:
| 方法 | 原理 | 工具 | | ---
| 方差过滤 | 删除方差小的列(波动小,无信息) | | | 相关系数 | 与目标的 / 相关性 | df.corr() | | 单变量评分 | f-value, chi2, | . |
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=1e-5) X_filtered = selector.fit_transform(X)
2. 包裹法( ) —— 模型亲测,有点“炼丹”味 常用方法:
| 方法 | 原理 | 优点 | | ---
| 递归特征消除(RFE) | 每次删掉不重要的特征,用模型重复训练 | 比较稳 | | / | 从少到多/多到少加减特征 | 直观 |
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
rfe = RFE(estimator=RandomForestClassifier(), n_features_to_select=20) X_selected = rfe.fit_transform(X, y)
3. 嵌入法() —— 直接利用模型自身的特征重要性 常用方法:
| 模型 | 方法 | | ---
| Lasso | L1 正则会把不重要特征权重压成 0 | | 决策树 / GBDT / | 自带 | | | 超强推荐,速度快,重要性可解释 |
import lightgbm as lgb
model = lgb.LGBMClassifier() model.fit(X, y) importance = pd.Series(model.feature_importances_, index=X.columns) top_features = importance.sort_values(ascending=False).head(30)
4. 基于稳定性的因子选择(金融量化专属)
from scipy.stats import spearmanr
ic_list = [] for col in X.columns: ic, _ = spearmanr(X[col], y) ic_list.append((col, ic))
ic_df = pd.DataFrame(ic_list, columns=["feature", "IC"]).sort_values("IC", ascending=False)
实战建议:
| 情况 | 推荐操作 | | ---
| 先快点跑一遍看哪些特征是废的 | 过滤法 | | 做建模数据集,搞模型准确率 | 嵌入法(LGB/) | | 做因子有效性分析(金融) | 计算 IC、IR | | 自动化多因子回测/研究 | 用因子池,每月选表现好的 |
自带特征选择!
这里我们用 自带特征选择来实现因子筛选。假如我们想通过因子来筛选未来5天会上涨的股票,这里花姐给出了一个简单的示例:
from tsfresh import select_features
import pandas as pd
from tsfresh.utilities.dataframe_functions import impute
def main(): df = pd.read_csv("01data.csv") df['date'] = pd.to_datetime(df['date'])
df_all_features = pd.read_csv("02data.csv") df_all_features['date'] = pd.to_datetime(df_all_features['date']) X = df_all_features.drop(columns=["date"])
df_label = df[['date', 'close']].copy() df_label['target'] = df_label['close'].shift(-5) > df_label['close'] df_label['target'] = df_label['target'].astype(int)
y = df_label[df_label['date'].isin(df_all_features['date'])]['target'].reset_index(drop=True)
impute(X) print("******************使用 tsfresh 进行特征选择**********************") X_selected = select_features(X, y)
print("******************输出选择后的因子**********************") print(f"选出来的有效因子数量:{X_selected.shape[1]}") print("部分有效因子名:", X_selected.columns[:10].tolist())
df_selected_features = df_all_features[['date']+X_selected.columns.tolist()] df_selected_features.to_csv("selected_features_with_data.csv", index=False) if __name__=="__main__": main()
看到这里你可能好奇 为啥一定要加 if name == ' main ':
你用的是 .(X, y) ,它在内部使用了 .Pool() 来加速计算。但是在 系统下 启动多进程时,会重新「导入整个主模块」,如果你没有加 if == '': , 会直接执行整个文件——就形成了无限递归「导入-执行-导入-执行」,然后炸锅!
所以不同于 Linux/macOS,需要你用:
if __name__ == '__main__':
来保护你的主逻辑。
画图看看因子是不是在扯淡
你没看错,就是画图。眼睛一看就知道因子灵不灵。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False
df_price = pd.read_csv("01data.csv", parse_dates=["date"]) df_features = pd.read_csv("selected_features_with_data.csv", parse_dates=["date"])
df_merged = pd.merge(df_price[['date', 'close']], df_features, on='date', how='inner')
feature_cols = [col for col in df_features.columns if col != 'date'][:10]
fig, ax1 = plt.subplots(figsize=(16, 8))
color = 'tab:blue' ax1.set_xlabel("日期") ax1.set_ylabel("收盘价", color=color) ax1.plot(df_merged['date'], df_merged['close'], color=color, label='收盘价', linewidth=2) ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx() ax2.set_ylabel("特征值")
colors = plt.cm.tab10.colors
for i, col in enumerate(feature_cols): ax2.plot(df_merged['date'], df_merged[col], label=col, linestyle='--', color=colors[i % 10])
ax2.tick_params(axis='y') fig.tight_layout()
lines1, labels1 = ax1.get_legend_handles_labels() lines2, labels2 = ax2.get_legend_handles_labels() ax1.legend(lines1 + lines2, labels1 + labels2, loc='lower right')
plt.title("收盘价 +
plt.grid(True) fig.tight_layout() plt.subplots_adjust(top=0.92) plt.show()
下一步预告:这些因子到底能不能赚钱?

量化交易很火?万亿成交量真是它搞出来的?一文说清楚
最近,量化交易真的挺火的,不少人都在传,万亿成交量就是量化交...(82 )人阅读时间:2025-07-24
1分钟找出3000个交易因子?真相来了!手把手教你用Pyth
我用1分钟给股票找出了3000个交易因子,用过的人都发财了炒...(184 )人阅读时间:2025-07-24
春节临近年终奖到账 银行理财密集上新 助力收益不打烊
春节临近,随着打工人年终奖的陆续到账,一场年味儿十足的年终奖...(80 )人阅读时间:2025-07-24
量化投资领域:基于掘金平台验证PE因子在信息技术行业适用性
一、前言:PE 因子的量化投资价值在量化投资领域,基本面因子...(62 )人阅读时间:2025-07-23 如自行操作,注意仓位控制和风险自负。)在股市中,所有牛股都是...
如自行操作,注意仓位控制和风险自负。)在股市中,所有牛股都是... 5月10日电 (龚宸芫)下周(5月12日—5月18日),中国...
5月10日电 (龚宸芫)下周(5月12日—5月18日),中国... 转自中国财经不知从什么时候开始,外汇这个无名英雄在中国已经变...
转自中国财经不知从什么时候开始,外汇这个无名英雄在中国已经变... 不妨一起看看2025生肖牛全年运势大全,了解这一年对你的生活...
不妨一起看看2025生肖牛全年运势大全,了解这一年对你的生活...